
反编译银河天使的tbl文件
title: 反编译银河天使的tbl文件
date: 2024-10-24 17:16:22
id: 4
tags:
- 汉化
- python
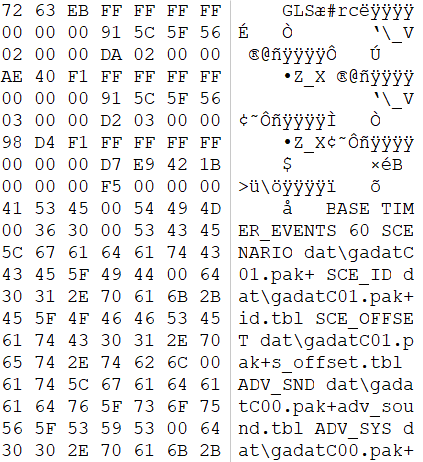
IIDX 4字节头部
数量:
4 = 节数量偏移
4(头部所占字节)+4 (节数量所占字节) + 节数量*4(字节)*2(类型标识 偏移) = 键值数量偏移
节:
节数量偏移 + 4 (节数量所占字节)
类型标识 节名偏移
键值:
键值数量偏移 + 4 (键值数量所占字节) = 键值起始偏移
节标识 键值标识 占位值 键值偏移 值偏移 下个键值偏移
字符:
键值起始偏移 + 键字节数量*6(节标识 键值标识 占位值 键值偏移 值偏移 下个键值偏移) *4(字节) = 字符总字节数偏移
字符总字节数偏移 + 4 = 字符起始偏移
实例:
初代ga_base.tbl
我们先读取位置4,得到节数量为5
根据节数量计算出键值数量偏移:524+4+4 = 48
读取位置48,得到键值数量为62
根据键值数量偏移和键值数量计算字符结束偏移:48+4+6264 = 1540
所以字符偏移就是:1540+4 = 1544
用已知数据来获取一下第1个节名吧:
节起始偏移:4+4 = 8
读取得到:
类型标识:0x1b42e9d7
节名偏移:0x0
字符偏移 + 节名偏移:1544+0 = 1544
读一下这个位置,发现是BASE,成功!
继续获取第1个键值名:
键值偏移:48+4 = 52
读取得到:
节标识:0x1b42e9d7
键值标识:0x8032913e
占位值:0xffffffff
键值偏移:0x140
值偏移:0x146
下个键值偏移:0x1b
发现没有?键值里的节标识与节里的是一致的,也就是说,这个键值是BASE类的
键值标识类似节标识,不过对我们来说似乎用处不大,不过要编译别忘了就是了
占位值更没用了,而且所有的占位值都是0xffffffff
键名偏移:1544+0x140 = 1864
键名长度:0x146-0x140-1= 5
值偏移:1544+0x146 = 1870
值长度:0x1b-1 = 0x1a
(虽然我写脚本没用长度直接识别的00结束)
读取结果:
键名:MOVIE
值: dat\gadat000.pak+movie.tbl
还原成未编译文件就是:
[BASE]
MOVIE=dat\gadat000.pak+movie.tbl
另外发现还有#纯数字的键名,不在字符里,就不过多赘述了,下面的脚本里有判断
写个简陋的Python脚本
import struct
import sys
import os
def read_int(file, offset):
file.seek(offset)
return struct.unpack('<I', file.read(4))[0]
def read_string(file, offset):
file.seek(offset)
result = b''
while True:
char = file.read(1)
if char == b'\x00' or not char: # 如果读取到空字符或文件结束,则停止
break
result += char
return result
def parse_iidx(file_path):
with open(file_path, 'rb') as file:
if not file.read(4) == b'IIDX':
print(f"{file_path} 文件头不符,跳过")
return
section_count_offset = 4
section_count = read_int(file, section_count_offset)
# 计算键值数量偏移
key_value_offset = 4 + 4 + section_count * 8
# 读取键值数量
key_value_count = read_int(file, key_value_offset)
# 计算字符结束偏移
char_end_offset = key_value_offset + 4 + key_value_count * 24
char_start_offset = char_end_offset + 4
# 存储节名和对应的键值对
sections = {}
# 遍历所有节
section_start_offset = section_count_offset + 4
for i in range(section_count):
section_type_id = read_int(file, section_start_offset)
section_name_offset = read_int(file, section_start_offset + 4)
section_name = read_string(file, char_start_offset + section_name_offset)
sections[section_type_id] = {"name": section_name, "keys": []}
section_start_offset += 8 # 移动到下一个节的起始偏移
# 遍历所有键值对
key_value_start_offset = key_value_offset + 4
for i in range(key_value_count):
key_section_id = read_int(file, key_value_start_offset)
key_id = read_int(file, key_value_start_offset + 4)
padding = read_int(file, key_value_start_offset + 8) # 占位值,无用
key_offset = read_int(file, key_value_start_offset + 12)
value_offset = read_int(file, key_value_start_offset + 16)
next_key_offset = read_int(file, key_value_start_offset + 20)
# 检查占位值是否为0xFFFFFFFF
if padding != 0xFFFFFFFF:
padding_dec = int(f"{padding:X}", 16)
key_name = f"#{padding_dec}".encode() # 使用占位值作为键名
else:
key_name = read_string(file, char_start_offset + key_offset)
value = read_string(file, char_start_offset + value_offset)
# 存储键值对和它们的值偏移量
sections[key_section_id]["keys"].append((key_name, value, value_offset))
key_value_start_offset += 24 # 移动到下一个键值对的起始偏移
# 将键值对添加到对应的节,并根据值偏移量排序
for section_id, content in sections.items():
content["keys"].sort(key=lambda x: x[2])
# 写入文件
with open(file_path, "wb") as output_file:
for section_id, content in sections.items():
output_file.write(b"[" + content["name"] + b"]\n")
for key, value, _ in content["keys"]:
output_file.write(b"=".join([key, value]) + b"\n")
output_file.write(b'\n')
print(f'文件 {os.path.basename(file_path)} 生成成功!\n共:\n{section_count}个节\n{key_value_count}对键值')
def process_directory(directory_path):
if not os.path.exists(directory_path):
print("指定的目录不存在")
return
for root, dirs, files in os.walk(directory_path):
for file in files:
if file.endswith('.tbl') or file.endswith('.idx') or file.endswith('.iidx'):
file_path = os.path.join(root, file)
parse_iidx(file_path)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("用法:python ga_all_tbl.py <directory_path>")
else:
directory_path = sys.argv[1]
process_directory(directory_path)
随便解个文件试试
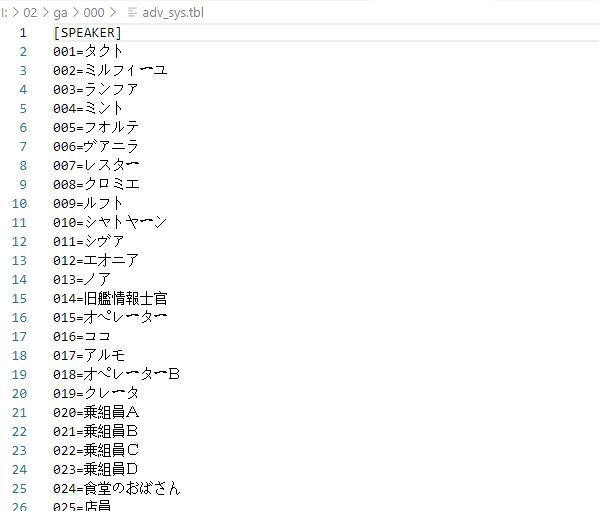
以上~~
评论